Så här optimerar du enkelsidor för sökmotorer
När Google och andra sökmotorer indexerar webbplatser utförs de inte JavaScript. Det här verkar som att sätta sidor för enskilda sidor - varav många är beroende av JavaScript - med en enorm nackdel jämfört med en traditionell webbplats.
Att inte vara på Google kan lätt betyda död för ett företag, och det här skrämmande fallgropet kan fresta uninformed att helt och hållet överge enskilda sidor.
Enstaka sidsajter har dock en fördel jämfört med traditionella webbplatser i sökmotoroptimering (SEO) eftersom Google och andra har erkänt utmaningen. De har skapat en mekanism för sidsidor för att inte bara få sina dynamiska sidor indexerade, men också optimera sina sidor specifikt för sökrobotar.
I den här artikeln kommer vi att fokusera på Google, men andra stora sökmotorer som Yahoo! och Bing stöder samma mekanism.
Hur Google söker igenom en enda webbsida
När Google indexerar en traditionell webbplats, skannar sin webbrobot (kallad Googlebot) först innehållet i den högsta URI-nivån (till exempel www.myhome.com). När det här är klart, följer det sedan alla länkar på den sidan och indexerar också de sidorna. Det följer sedan länkarna på de följande sidorna, och så vidare. Så småningom indexerar det allt innehåll på webbplatsen och tillhörande domäner.
När Googlebot försöker indexera en enda sidsajt, ser allt som det ser ut i HTML-en en enda tom behållare (vanligen en tom div- eller kroppslabel), så det finns ingenting att indexera och inga länkar att granska, och det indexerar webbplatsen i enlighet därmed ( i den runda cirkulära "mappen" på golvet bredvid sitt skrivbord).
Om det var slutet på historien skulle det vara slutet på enstaka sidor för många webbapplikationer och webbplatser. Lyckligtvis har Google och andra sökmotorer insett vikten av webbsidor och tillhandahålls verktyg för att ge utvecklare möjlighet att tillhandahålla sökinformation till sökroboten som kan vara bättre än traditionella webbplatser.
Så här gör du en sida för en sida som kan krypas
Den första nyckeln till att kryptera vår enkelsidans webbplats är att inse att vår server kan berätta om en begäran görs av en sökrobot eller en person som använder en webbläsare och svarar i enlighet därmed. När vår besökare är en person som använder en webbläsare, svara som vanligt, men för en sökrobot, returnera en sida optimerad för att visa sökroboten exakt vad vi vill, i ett format som sökroboten lätt kan läsa.
På hemsidan på vår sida, hur ser en sökrobotoptimerad sida ut? Det är förmodligen vår logotyp eller annan primärbild som vi skulle vilja visas i sökresultat, någon SEO optimerad text som förklarar vad webbplatsen är eller gör och en lista med HTML-länkar till endast de sidor som vi vill att Google ska indexera. Vad sidan inte har är någon CSS-styling eller komplex HTML-struktur som tillämpas på den. Det har inte heller några JavaScript, eller länkar till områden på webbplatsen som vi inte vill att Google ska indexera (t.ex. juridiska ansvarsfriskrivningssidor eller andra sidor som vi inte vill att folk ska komma in via en Google-sökning). Bilden nedan visar hur en sida kan presenteras för en webbläsare (till vänster) och till sökroboten (till höger).
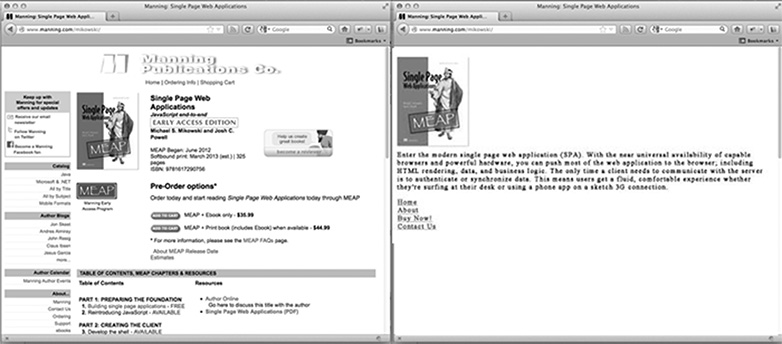
Anpassa innehåll för sökrobotar
Vanligtvis länkar enskilda sidor till olika innehåll med hjälp av ett hash-bang (#!). Dessa länkar följer inte på samma sätt av personer och sökrobotar.
Till exempel, om på vår enkelsidans webbplats en länk till användarsidan ser ut som /index.htm#!page=user:id,123 , skulle sökroboten se #! och vet att du letar efter en webbsida med URI / index.htm?_escaped_fragment_= page =user:id,123 . Att veta att sökroboten följer mönstret och letar efter den här URIen, kan vi programmera servern för att svara på den förfrågan med en HTML-snapshot av den sida som normalt skulle göras av JavaScript i webbläsaren.
Den ögonblicksbilden indexeras av Google, men alla som klickar på vår lista i Googles sökresultat tas till /index.htm#!page=user:id,123 . Sidan JavaScript kommer att ta över därifrån och göra sidan som förväntad.
Detta ger utvecklare av enstaka sidor möjlighet att skräddarsy sin webbplats specifikt för Google och specifikt för användare. I stället för att behöva skriva text som är både läsbar och attraktiv för en person och förståelig av en sökrobot, kan sidor optimeras för varje utan att oroa sig för den andra. Webbläsarens sökväg via vår webbplats kan kontrolleras, så att vi kan rikta personer från Googles sökresultat till en specifik uppsättning ingångssidor. Detta kommer att kräva mer arbete hos ingenjören att utvecklas, men det kan ha stora utbetalningar vad gäller sökresultatposition och kundretention.
Upptäcka Googles webbrobotare
Vid tidpunkten för detta skrivande meddelar Googlebot sig som en sökrobot till servern genom att göra förfrågningar med en användaragentsträng av Googlebot / 2.1 (+ http://www.googlebot.com / bot.html) . En Node.js-applikation kan söka efter den här användaragentsträngen i middleware och skicka tillbaka den sökrobotoptimerade hemsidan om användaragentsträngen matchar. Annars kan vi hantera begäran normalt.
Denna arrangemang verkar som om det skulle vara komplicerat att testa, eftersom vi inte äger Googlebot. Google erbjuder dock en tjänst för att göra detta för offentligt tillgängliga produktionswebbplatser som en del av dess webbansvariga verktyg, men ett enklare sätt att testa är att spoofa vår användaragentsträng. Detta brukade kräva lite kommandoradshackeri, men Chrome Developer Tools gör det så enkelt som att klicka på en knapp och markera en ruta:
Öppna Chrome Developer Tools genom att klicka på knappen med tre horisontella linjer till höger om Google Verktygsfält och sedan välja Verktyg från menyn och klicka på Utvecklarverktyg.
I det nedre högra hörnet av skärmen finns en kugghjulsikonen: klicka på det och se några avancerade utvecklingsalternativ som inaktivera cacheminnet och aktivera loggningen av XmlHttpRequests.
Klicka på kryssrutan bredvid användaragentetiketten och välj ett antal användaragenter i rullgardinsmenyn från Chrome, Firefox, IE, iPads och mer i den andra fliken, som heter Overrides . Googlebot-agenten är inte ett standardalternativ. För att använda den, välj Annan och kopiera och klistra in användaragentsträngen i den angivna inmatningen.
Nu är fliken spoofing sig som en Googlebot, och när vi öppnar någon URI på vår webbplats ska vi se sidan för sökroboten.
Sammanfattningsvis
Självklart kommer olika applikationer att ha olika behov när det gäller vad som ska göras med webblåsare, men det är förmodligen inte tillräckligt med en sida som returneras till Googlebot. Vi måste också bestämma vilka sidor vi vill avslöja och ge sätt att vår applikation kan kartlägga _escaped_fragment_ = key = värdet URI till det innehåll vi vill visa dem.
Du kanske vill bli snygg och knyta serverns svar till fronten-ramen, men jag brukar använda det enklare tillvägagångssättet här och skapa anpassade sidor för sökroboten och placera dem i en separat routerfil för sökrobotar.
Det finns också mycket mer legitima sökrobotar där ute, så när vi justerat vår server för Google-sökroboten kan vi expandera för att inkludera dem också.
Byggar du enstaka sidor? Hur fungerar enskilda sidor på sökmotorer? Låt oss veta dina tankar i kommentarerna.